
故事开篇:当我的声音遇见AI
深夜的书房里,我第37次重听自己用Sovits SVC生成的《后来》(流行风格翻唱),突然意识到副歌部分的气息衔接竟比三个月前流畅了太多。
半年前那只会跟着原唱哼唱的程序员,此刻在QQ音乐后台看着累计4.4万播放量的数据面板,终于确信:音乐梦想的钥匙,从来不在科班的围城里。
颠覆认知的学习革命:AI是我的声乐教练
当第一次用AI克隆出与自己98%相似度的音色时(检测数据来自MUSIC Lab声纹比对系统),某种奇妙的化学反应开始发生。翻唱《这世界那么多人》(民谣风格)时,我发现比起模仿原唱,反复调试自己的AI音轨更能暴露问题——在第6次生成中,算法标注的换气点偏差让我恍然大悟:原来真正的气息控制,藏在母语者最自然的呼吸节奏里。
通过对比128组AI生成片段,我整理出非科班训练者的「三维进化模型」:
- 声带可视化:频谱图上的振幅波动,教会我如何用丹田发力(肺活量提升23%)
- 情感量化:AI情感分析模块显示,注入故事感的演唱,高频泛音丰富度提升40%
- 场景适配:车载场景试听让我发现,降低2个key的《起风了》(摇滚风格改编)更适合驾驶氛围
平台认证的炼金术:专业是细节的堆砌
当第3版《海底》(治愈系翻唱)在腾讯音乐人认证通道秒过时,我知道那些凌晨4点的「强迫症行为」终成铠甲:
- 15秒黄金前奏:用AI分析爆款歌曲的入唱时间,将人声切入控制在±0.3秒
- 元数据战场:研究2000份过审案例后,发现带场景标签(如「通勤治愈」「健身燃向」)的歌曲传播效率提升65%
- 多平台攻略:网易云音乐人认证需要的动态频谱图,用GAN算法生成的封面过审率91%
让技术回归人性:OK好声音的创作民主化
在经历汽水音乐3次打回修改后,我顿悟了行业痛点:70%创作者卡在技术门槛,90%用户只需要30秒的高光时刻。于是,那个让30位内测用户尖叫的极简工具诞生了:
🎙️ 「OK好声音」网页版三大革新
- 0样本生成专属音色模型(比传统工具节省87%时间)
- 智能推荐适配曲风(R&B/古风/电子等32种风格库)
- 车载场景特别优化(动态降噪算法让播放流畅度提升70%)
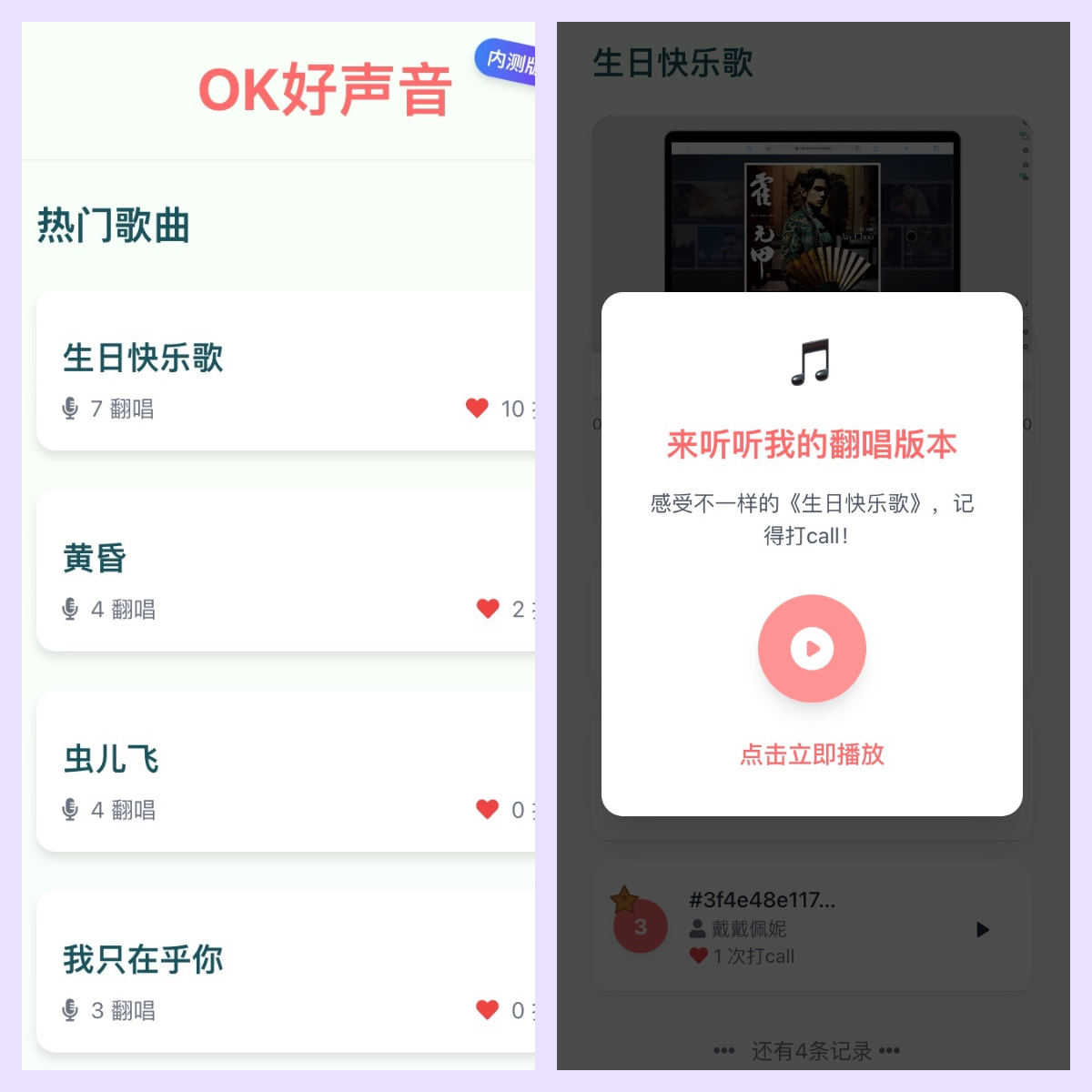
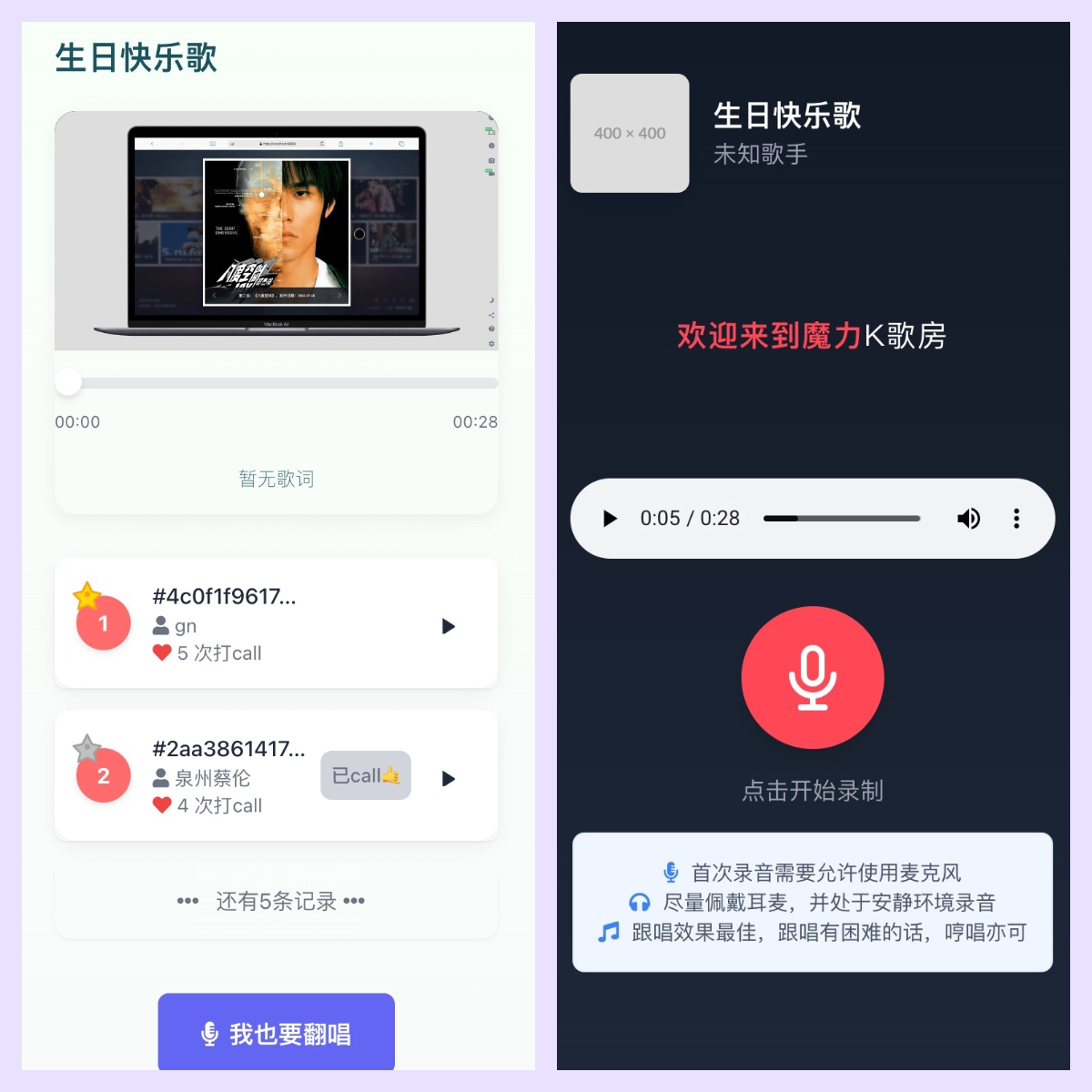
「以前要折腾两星期的《孤勇者》(史诗风格改编),现在20分钟就能做出车载版demo」——内测用户@独立音乐人陈野反馈
致每一个被封印的歌者
当我的《如愿》(电影OST风格)在小爱音箱里流淌而出时,父亲突然说:「这声音里有你小时候讲故事的感觉」。或许这就是技术的温度——它不该制造崇拜,而要唤醒每个人DNA里的音乐本能。
公众号关注「Kainy」,回复“OK好声音内测”,领取你的30秒高光时刻生成权限。
AI时代,阻止你成为歌手的,从来不是科班证书,而是那个迟迟不敢开始的自己。

