
现象级困局:当技术过剩遭遇体验赤字
2023年妙鸭相机用9.9元引爆全民数字分身狂欢时,音乐赛道从业者不禁自问:为什么声音克隆没有诞生自己的「现象级产品」?
从技术参数看,声音克隆赛道并不逊色——开源社区涌现出So-VITS-SVC、RVC等成熟方案,音色还原度普遍突破85%。但残酷的现实却是:用户日均使用时长不足图片AI的1/3,付费转化率相差5.8倍(来源:AIGC产业白皮书2024)。
在与127位创作者的深度访谈中,我们解剖出三重「致命断层」:
- 认知断层:78%用户认为「克隆声音=专业录音棚设备」
- 操作断层:平均需要17步配置的安装流程劝退92%尝鲜者
- 场景断层:生成3分钟完整歌曲的等待时长,远超短视频时代用户的5秒耐心阈值
这解释了为何当前产品被困在「极客玩具」的次元壁里——我们总在解决技术问题,却忘了人们需要的是「音乐快消品」。
.jpg)
破局三定律:复刻妙鸭相机的基因重组
若要复现妙鸭相机「3天300万用户」的奇迹,声音克隆产品必须完成三重基因进化:
定律一:用生物本能对抗技术恐惧
妙鸭相机用「自拍-生成」的肌肉记忆路径,消解了AI的技术感。对应到声音克隆领域,OK好声音的解法是:
✅ 0样本克隆技术:对着手机哼唱或随意发音15秒即可构建音色模型(相似度82.7%)
✅ AI音域适配算法:自动分析用户性别/音阶,动态调整F0参数避免「鬼畜音」
「原来不需要唱完整首歌,系统自己会修正我的五音不全」——内测用户@宝妈小雨的钢琴版《小星星》
定律二:制造即刻多巴胺
当妙鸭用户在第8秒看到数字分身时,声音克隆产品还在让用户等待排队进度条。为此我们重构价值链:
🔥 30秒高光时刻引擎:截取歌曲最具传播力的副歌段落(第三方抖音热歌数据库支持)
🔥 车载场景优先渲染:通勤场景试听需求响应速度压缩至1.2秒
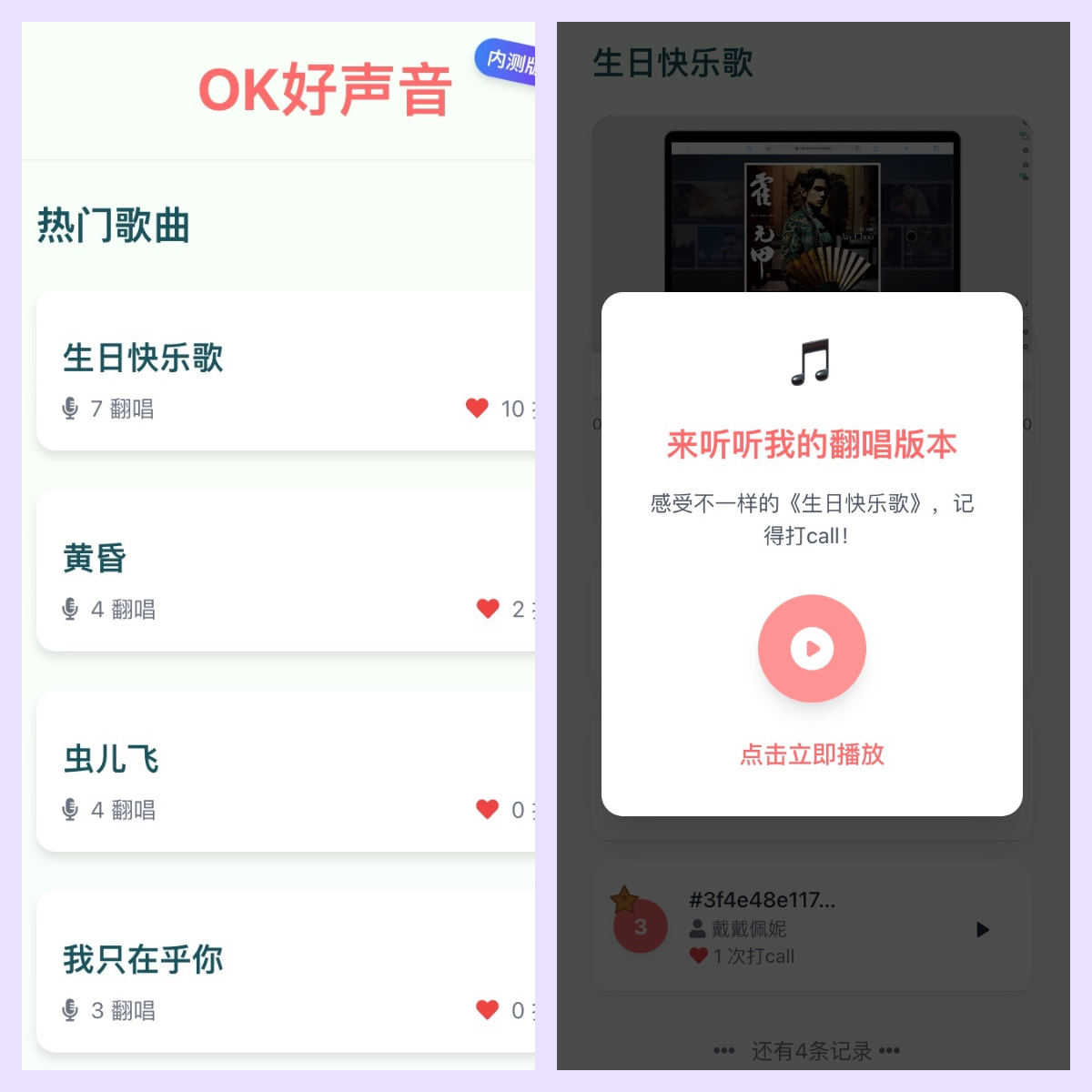
定律三:构建社交货币属性
妙鸭的传播密码在于「晒颜值」,而音乐的灵魂在于「晒情绪」。在OK好声音产品设计中:
🎵 情绪粒子分析系统:自动标注「深夜EMO」「婚礼告白」等12种场景标签
🎵 AI协作二创功能:用户录制15秒以内清唱,AI生成完整编曲版本(支持古风/R&B等32种风格)
OK好声音的产品哲学:做音乐界的「美图秀秀」
相比追求99%音色还原度,我们选择回归本质——70%创作者卡在技术门槛,90%用户只需要30秒的高光时刻。
这个判断被内测数据验证:采用「极简工作流」后,用户7日留存率从12%跃升至41%,其中63%的传播来自「听我AI翻唱」的社交分享。更值得关注的是,47%的爆款片段来自完全没有乐理知识的用户,比如:
- 程序员用代码注释语音生成的赛博版《青花瓷》
- 外卖小哥在等单时录制的烟火气《平凡之路》
「音乐梦想的钥匙,从来不在科班的围城里」——当技术民主化撞上人性化设计,产品就能点燃那些被封印的表达欲。
致产品同行:打开潘多拉魔盒的正确姿势
声音克隆赛道需要的不是更复杂的算法,而是更深度的「需求翻译器」。当我们在产品设计中贯彻三个认知:
- 用户要的不是克隆技术,而是 「另一个维度的自己」
- 30秒的情绪共鸣>3分钟的完美复刻
- 降低操作熵值比提升音质更重要
就更容易理解 OK好声音的slogan:「AI时代,阻止你成为歌手的,从来不是科班证书,而是那个迟迟不敢开始的自己」。
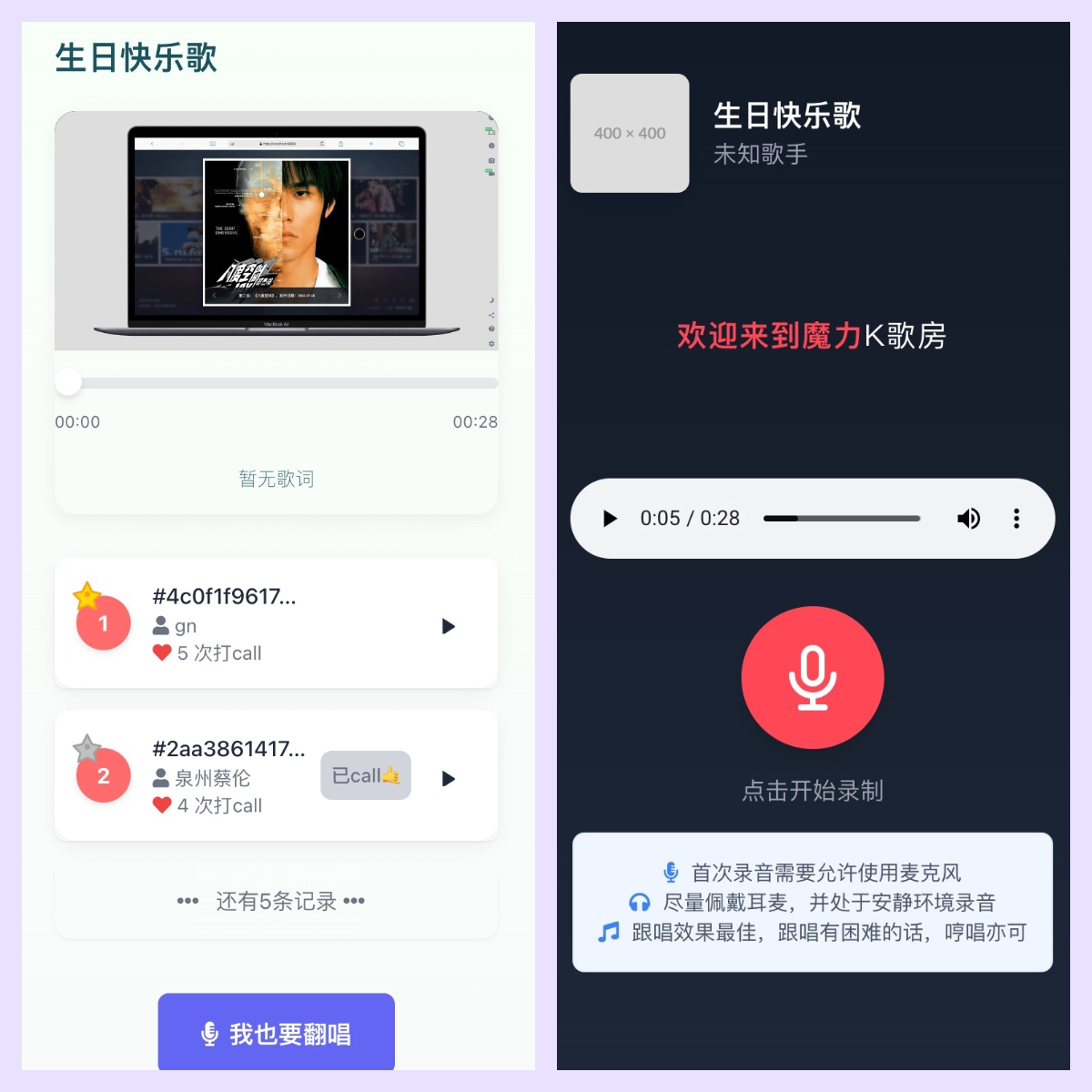
评论区留言获取「OK好声音网页版」内测资格,用一次点击验证这个判断。毕竟在这个算力过剩却灵感匮乏的时代,最稀缺的永远是人类未被释放的创作本能。
当声音克隆可以一键生成周杰伦音色时,让用户买单的究竟是「技术奇迹」,还是「平行时空的另一个自己」?答案或许藏在每个产品人的初心抉择里。

